Bölüm5 Temel Nesneler
Bu bölümde kodlama için ihtiyaç duyacağınız temel yapılar açıklanacak ve uygulamalar ile desteklenecektir. Farklı uygulamalar ders esnasında eş zamanlı yapılacağından lütfen online dersleri takip ediniz.
5.1 Aritmetik (Arithmetic)
R, en basit haliyle hesap makinesi olarak kullanılabilir. Toplama +, çıkarma -, çarpma *, bölme / operatörleri ile gerçekleştirilir.
5+4## [1] 9Birden fazla matematiksel işlem aynı satırda gerçekleştirilebilir.
3+4; 6*4; 10-2## [1] 7## [1] 24## [1] 8İşlemler parantez yardımıyla önceliğine göre yazılabilir, yazılmadığı taktirde matematiksel işlem önceliği geçerlidir.
10*2-3## [1] 17İşlem devam edecek biçimde tanımlanırsa console + simgesi ile devam edecek ve işlem tamamlanana kadar yeni işleme geçmenize engel olacaktır. İşlemi tamamlamalı veya yeni işleme geçmek için esc tuşunu kullanmalısınız.
10+20+30+
40## [1] 100Yapılan işlemler sonucu elde edilen çok büyük veya çok küçük sonuçlar için output exponent olarak verilir.
12000*3000## [1] 3.6e+071.3e2 (130 anlamına gelir. e2: ondalık noktasını iki basamak sağa taşı)
1.4e-1 (0.14 anlamına gelir. e-1: ondalık noktasını bir basamak sola taşı)
Uygulamada elde edilen sonucun integer (tamsayı) olması gerekebilir. Bu noktada elde edilen output üste, alta veya 0.5 üzeri ya da altı olma durumuna göre farklı komutlar yardımı ile yuvarlanabilir.
- floor: alta yuvarla
floor(5.2); floor(5.7)## [1] 5## [1] 5- ceilign: üste yuvarla
ceiling(3.2); ceiling(3.8)## [1] 4## [1] 4- round: 0.5 üzeri ise üste, 0.5 altı ise alta yuvarla
round(5.6); round(5.3)## [1] 6## [1] 5Negatif sayılarda komutların nasıl işlediğini inceleyebilirsiniz.
round komutu ile virgülden sonra kaç basamak olması gerektiğini belirterek yuvarlama işlemi yapabilirsiniz.
round(1.248,2)## [1] 1.25Kullanılabilecek matematiksel fonksiyonlara örnek olarak (Crawley 2012)

5.2 Nesneleri Tanımlama (Assigning Objects)
Temel işlevlerden bir diğeri kullanılacak değişkenlerin tanımlanmasıdır. Değişken için seçilecek isim mümkün olan en kısa haliyle tanımlanarak kavram kargaşası önlenmelidir.
R, büyük ve küçük harfe duyarlıdır, dolayısıyla tanımlanan \(B\) ve \(b\) iki farklı değişkeni temsil eder.
Değişken ismi iki veya daha fazla kelimeden oluşacaksa kelimeler arasında boşluk yerine nokta kullanılmalıdır. (
neura link)Değişken ismi sayı veya sembol ile başlayamaz. (
1a,&b)
Değişken tanımlama işlemi <- operatörü ile gerçekleştirilir. Tanımlanan değişken adı ile çağrılmazsa veya print komutu kullanılmazsa çıktı yazdırılmaz.
x<-3
print(x)## [1] 3Sayısal olmayan değer tanımlamaları tırnak içerisinde yapılmalıdır.
msg<- "hello world"Tanımlanan değişken veya fonksiyon ile ilgili notlar # ile tanımlanır.
x.ort<-20 # ortalama değerÇıktıda basılan [.] kaçıncı gözlemden devam edildiğini gösterir. Örneğin 30 gözleminin [26] ifadesinin yardımı ile 26. gözlem olduğunu kolaylıkla söyleyebiliriz. [.] ifadeleri asıl seride yer almaz, yalnızca yol gösterici olarak çıktıda gözlenir.
x<-5:50
x## [1] 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
## [26] 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 505.3 Vektörler (Vectors)
Vektör oluşturmak için c() operatör kullanılmaktadır. Vektörler
- numeric
- character
- logical
- integer
- complex
yapıları içerebilir. Vektörler yalnızca aynı yapıda gözlemler içerebilir.
x <- c(0.5, 0.6) # numeric
x <- c(TRUE, FALSE) # logical
x <- c(T, F) # logical
x <- c("a", "b", "c") # character
x <- 9:29 # integer
x <- c(1+0i, 2+4i) # complexT ve F, TRUE ve FALSE’a karşılık kullanılan kısaltma yapılardır.
x <- c(T, F) # logical
x## [1] TRUE FALSEAynı zamanda vector komutu ile de vektör oluşturabilirsiniz. Vektörü tanımlarken belirlenen içerik yapısına göre oluşturulur.
x <- vector("numeric", length = 7)
x## [1] 0 0 0 0 0 0 0Complex elemanları içerecek bir vektör oluşturmak istendiğinde;
x <- vector("complex", length = 7)
x## [1] 0+0i 0+0i 0+0i 0+0i 0+0i 0+0i 0+0iAynı değişken adı birden fazla tanımlamada kullanılırsa yapılan son tanımlama geçerli olacaktır. Kod yazarken kullandığınız değişken isimlerine ve doğru yazıma dikkat ediniz.
Vektör uzunluğu length() komutu ile sorgulanır.
x<-c(1:68)
length(x)## [1] 68Vektör aynı yapıda gözlemlerden oluşmuyorsa?
Bu durumda tüm gözlemler tek bir yapı olarak algılanır. Herhangi bir değişkenin hangi yapıda gözlem içerdiği class() komutu ile sorgulanabilir.
y <- c(1.7, "a") # character
class(y)## [1] "character"y <- c(TRUE, 2) # numeric
class(y)## [1] "numeric"y <- c("a", TRUE) # character
class(y)## [1] "character"Vektör farklı yapıda gözlemler için verimli kullanılamıyor olabilir ancak bu işlemi gerçekleştirebilen
listkomutu mevcuttur. İlerleyen başlıklarda bu komut detaylandırılacaktır.
Kodlama yaparken sıklıkla kullanılan bir işlem türü de vektör yapısının değiştirilmesidir. Vektör içeriğinin aynı yapıda olması kuralına sadık kalarak tüm vektör içeriği farklı bir yapıya aktarılabilir. Burada as.numeric, as.logical gibi komutlardan faydalanılır.
x <- 0:6
class(x)## [1] "integer"x vektörünün integer yapıda olduğunu gördükten sonra as.character komutu ile yeni x vektörünü character olarak tanımlayabiliriz.
x<-as.character(x)
x; class(x)## [1] "0" "1" "2" "3" "4" "5" "6"## [1] "character"Bazı durumlarda R dönüşüm için çözüm üretemez ve NA çıktı verir.
x <- c("a", "b", "c")
as.numeric(x)## Warning: NAs introduced by coercion## [1] NA NA NAR, eksik gözlemleri NA (non available) olarak tanımlar. İmkansız değerleri ise NaN (not a number) olarak tanımlar.
Sık kullanılan komutlardan bir diğeri seq(), bu fonksiyon sayesinde istediğiniz aralıkta ve artış seviyesinde vektör üretebilirsiniz.
x<-1:20 #1'den 20'ye 1'er artan seri
x## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20x<-seq(from=5,to=20,by=5) #5'den 20'ye 5'er artan seri
x## [1] 5 10 15 20Serinin bitiş noktasını belirtmeden de tanımlama yapmak mümkündür, bu durumda serinin uzunluğunun ne olduğun fonksiyonda belirtilmelidir.
x<-seq(from=0.04,by=0.01,length=11)
x## [1] 0.04 0.05 0.06 0.07 0.08 0.09 0.10 0.11 0.12 0.13 0.14Gözlemleri sıralamak için sort() komutu kullanılır. sort() kodu default olarak küçükten büyüğe sıralama yapar, sıralama yönünü değiştirme işlemi decreasing ile gerçekleştirilir.
y <- c(4,2,0,9,5,3,10)
sort(y)## [1] 0 2 3 4 5 9 10sort(y, decreasing=TRUE) # büyükten küçüğe sıralama## [1] 10 9 5 4 3 2 0Tekrarlı oralarak işlem yapmak için kullanılan fonksiyon rep() şeklinde tanımlanmaktadır.
rep(y,times=3)## [1] 4 2 0 9 5 3 10 4 2 0 9 5 3 10 4 2 0 9 5 3 10Vektörler için kullanışlı fonksiyonlardan bazıları aşağıdaki listede sizlerle paylaşılmıştır (Crawley 2012).
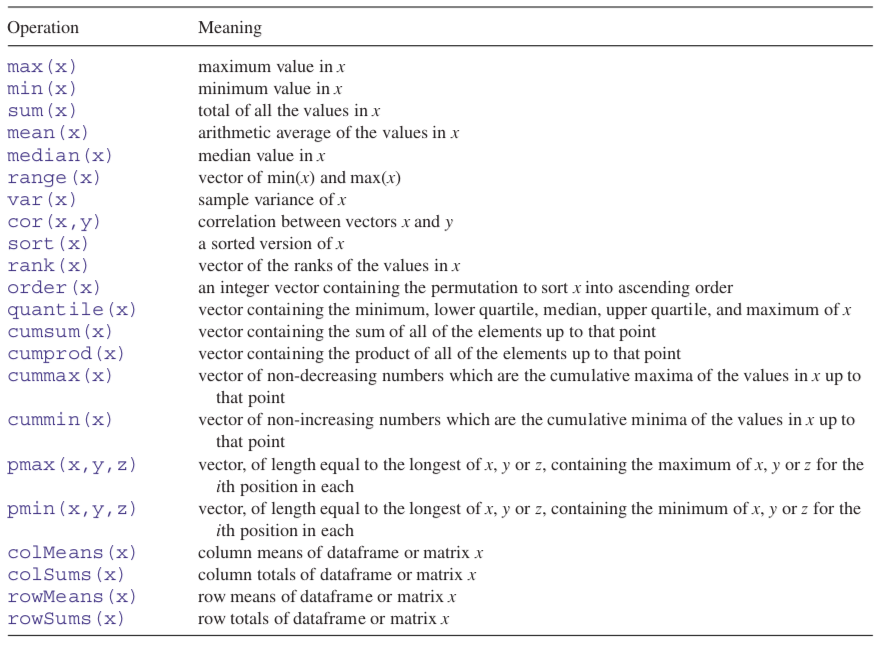
5.4 Matrisler (Matrices) ve Diziler (Arrays)
Matrisler, boyut niteliğine sahip vektörlerdir. Matris yapısında satır (row) ve sütun (column) (\(r*c\)) olmak üzere iki boyut mevcuttur. Matris içeriği de vektörde olduğu gibi tek tip yapıdan oluşmalıdır. m içeriği boş bir matris olmak üzere;
m <- matrix(nrow = 2, ncol = 3)
m## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] NA NA NAMatris boyutu dim() komutu ile sorgulanır.
dim(m)## [1] 2 3Matris yapısında gözlemler sütun şeklinde sıralanır.
m <- matrix(1:6, nrow = 2, ncol = 3)
m## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6Elemanların aynı satırdan devam ettiği matris üretmek isteniyorsa byrow=TRUE bilgisi eklenmelidir.
n<-matrix(1:6,2,3,byrow = TRUE); n## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6Vektörler parçalanarak da matris yapısı oluşturabilirler.
m <- 1:10 ;m## [1] 1 2 3 4 5 6 7 8 9 10dim(m) <- c(2, 5) ;m## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10Matrisler, satır veya sütunların birleştirilmesi yoluyla da oluşturulabilir. Satıların bir araya getirilmesi için rbind komutu kullanılırken, sütunların bir araya getirilmesi için cbind komutu kullanılmaktadır.
x <- 1:3
y <- 10:12
cbind(x, y)## x y
## [1,] 1 10
## [2,] 2 11
## [3,] 3 12rbind(x, y)## [,1] [,2] [,3]
## x 1 2 3
## y 10 11 12[,4] anlamı ilgili değişkenin 4. sütunu tüm satırları
[2,] anlamı ilgili değişkenin 2. satırı tüm sütunları
Mevcut yapıyı sorgulamak ve değiştirmek de mümkündür.
x<-c(1,2,3,4,5,6,7,8,9);x## [1] 1 2 3 4 5 6 7 8 9is.vector(x)## [1] TRUEy<-as.matrix(x);y## [,1]
## [1,] 1
## [2,] 2
## [3,] 3
## [4,] 4
## [5,] 5
## [6,] 6
## [7,] 7
## [8,] 8
## [9,] 9class(y)## [1] "matrix" "array"Matrisin transpozu t() fonksiyonu ile alınır.
m1<-matrix(c(1:8),4,2);m1## [,1] [,2]
## [1,] 1 5
## [2,] 2 6
## [3,] 3 7
## [4,] 4 8t(m1) ## [,1] [,2] [,3] [,4]
## [1,] 1 2 3 4
## [2,] 5 6 7 8Matrislerde satır ve sütunlar için isim tanımlama işlemi satır veya sütun tanımlamasına bağlı olarak sırasıyla rownames() ve colnames() fonksiyonları ile gerçekleştirilir.
rownames(m1)<-c("x1","x2","x3","x4")
colnames(m1)<-c("y1","y2"); m1## y1 y2
## x1 1 5
## x2 2 6
## x3 3 7
## x4 4 8Matrislerde işlem kolaylığı sağlamak adına bazı fonksiyonlar tanımlanmıştır. Satır toplam veya ortalama, sütun toplam veya ortalama işlemleri için tanımlı fonksiyonlar aşağıda yer almaktadır.
rowSums(): satır toplam
colSums(): sütun toplam
rowMeans(): satır ortalama
colMeans(): sütun ortalama
rowSums(m1)## x1 x2 x3 x4
## 6 8 10 12colMeans(m1)## y1 y2
## 2.5 6.5Matrislerde çarpma işlemi %*% operatörü ile gerçekleştirilir.
c1<-matrix(c(1,2,3,4),2,2)
c2<-matrix(c(1,3,1,2),2,2); c1; c2## [,1] [,2]
## [1,] 1 3
## [2,] 2 4## [,1] [,2]
## [1,] 1 1
## [2,] 3 2c1*c2## [,1] [,2]
## [1,] 1 3
## [2,] 6 8c1%*%c2## [,1] [,2]
## [1,] 10 7
## [2,] 14 10Herhangi bir matrisin tersini alma işlemi solve() komutu ile gerçekleştirilir.
Diziler matrislerdeki satır ve sütune ek olarak bir boyut (h) daha içerir. Birden fazla matrisin yer aldığı \(r*c*h\) boyutlu bir yapı olarak düşünülebilir. Dizi içeriği aynı tipte verilerden oluşmalıdır.
array(1:12, dim = c(2, 2, 3))## , , 1
##
## [,1] [,2]
## [1,] 1 3
## [2,] 2 4
##
## , , 2
##
## [,1] [,2]
## [1,] 5 7
## [2,] 6 8
##
## , , 3
##
## [,1] [,2]
## [1,] 9 11
## [2,] 10 125.5 Listeler ve Data Frameler (Lists and Data Frames)
Listeler vektörlerin özel bir halidir. Vektörler içeriğinde aynı yapıda eleman bulundurma koşuluna sahipken, listeler için böyle bir koşul yoktur. Özetle, listeler farklı yapıda ve boyutta veri tiplerini içerebilir.
Liste oluşturmak için ihtiyaç duyulacak fonksiyon list()dir.
x <- list(c(1,2,3), "istatistik", TRUE, 1 + 4i);x## [[1]]
## [1] 1 2 3
##
## [[2]]
## [1] "istatistik"
##
## [[3]]
## [1] TRUE
##
## [[4]]
## [1] 1+4iBoş bir liste oluşturmak için vector() fonksiyonundan faydalanabilirsiniz.
x <- vector("list", length = 3);x## [[1]]
## NULL
##
## [[2]]
## NULL
##
## [[3]]
## NULLData frameler de iki boyutlu yapılardır. Sütun içerisinde veri tipi aynı olmalıdır ancak sütunlar arası veri tipi farklılık gösterebilir. Regresyon ve farklı istatistiksel hesaplamalarda data frameler sıklıkla kullanılır. Aynı zamanda as.data.frame() fonksiyonu yardımıyla matrisler data framelere dönüştürülebilir. Data frame yapısında yer alan değişkenlerin boyutlarının aynı büyüklükte olması gereklidir.
x<-data.frame(Gün=c("Pzts","Salı","Çarş","Perş", "Cuma"), Vaka=c(1000,1110,1125,1153,1196));x## Gün Vaka
## 1 Pzts 1000
## 2 Salı 1110
## 3 Çarş 1125
## 4 Perş 1153
## 5 Cuma 1196str komutu yardımıyla data frame yapısının içerik detaylarına ulaşılabilir.
str(x)## 'data.frame': 5 obs. of 2 variables:
## $ Gün : chr "Pzts" "Salı" "Çarş" "Perş" ...
## $ Vaka: num 1000 1110 1125 1153 1196
data olarak isimlendirilen data frame yapısındaki veri ile ilgili farklı seçim işlemleri aşağıdaki tabloda belirtilmiştir.

5.6 Sayısal Olmayan Değerler (Non-Numeric Values)
Programlama yaparken sayısal verilerin yanında sayısal olmayan veri tipleri de kullanılmaktadır. Sayısal olmayan veri tipleri;
- Mantık (logical)
- Karakter (character)
- Faktör (factor)
olmak üzere üç başlık altında toplanmaktadır.
5.6.1 Mantıksal Değerler
Mantıksal değerler TRUE veya FALSE olarak tanımlanabilir. Mantıksal değerler fonksiyonların içinde de sıklıkla kullanılmaktadır. Örneğin sort fonksiyonunda sıralamanın artan veya azalan olmasını belirleyen decreasing=FALSE, ya da matriste eleman dizilimini belirleyen byrow=TRUE gibi. TRUE ve FALSE kısaltması olarak T ve F de kullanılabilir.
p<-c(T,F,T,T,T,F,T,F);p## [1] TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE| Operatör | Anlamı |
|---|---|
| == | Eşittir |
| != | Eşit değildir |
| > | Büyüktür |
| < | Küçüktür |
| >= | Büyük eşittir |
| <= | Küçük eşittir |
1==2## [1] FALSE1>2## [1] FALSE1!=(2+5)## [1] TRUEh<-c(3,2,1,4,1,2,1,-1,0,3)
m<-c(4,1,2,1,1,0,0,3,0,4)
length(h)==length(m)## [1] TRUEh==m## [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSEİki mantıksal değeri karşılaştırmak için kullanılan operatörler ve sonuçlar

x<-c(T,F,F,T)
y<-c(F,F,T,T)
x&y## [1] FALSE FALSE FALSE TRUEx&&y## [1] FALSEx|y## [1] TRUE FALSE TRUE TRUEx||y## [1] TRUEMantıksal değerler ikili yapıları gereği 1 TRUE ve 0 FALSE olarak tanımlanır.
TRUE+TRUE## [1] 2T+T+F+T+T+T+F## [1] 51&&1## [1] TRUE1||0## [1] TRUEBenzer mantık işlemleri karakter veriler için de uygulanabilir.
"alpha"=="alpha"## [1] TRUE"alpha"!="beta"## [1] TRUE5.6.2 Karakterler
Diğer bir yaygın kullanılan veri tipi de karakterlerdir.
x<-"OpenAI, kâr amacı gütmeyen bir yapay zeka araştırma şirketidir."
x; length(x)## [1] "OpenAI, kâr amacı gütmeyen bir yapay zeka araştırma şirketidir."## [1] 1R, dizeyi tek bir varlık olarak ele alır. Diğer bir deyişle, x, 1 uzunluğunda bir vektördür çünkü R, tek tek sözcükler veya karakterler yerine yalnızca farklı dizelerin toplam sayısını sayar. Tek tek karakterlerin sayısını saymak için nchar fonksiyonunu kullanabilirsiniz.
nchar(x)## [1] 63
cat-writing-animation
cat ve paste yardımıyla birleştirmek istediğiniz argümanları bir araya getirebilirsiniz.
gpt3<-c("içerik üretmek için derin öğrenmeyi kullanan",
"Generative Pre-trained Transformer 3",
"insanların yazdığı metinlere benzer")cat(gpt3[2],"(kısaca GPT-3)",",",gpt3[3],gpt3[1],"özbağlanımlı dil modelidir.")## Generative Pre-trained Transformer 3 (kısaca GPT-3) , insanların yazdığı metinlere benzer içerik üretmek için derin öğrenmeyi kullanan özbağlanımlı dil modelidir.paste(gpt3[2],"(kısaca GPT-3)",",",gpt3[3],gpt3[1],"özbağlanımlı dil modelidir.")## [1] "Generative Pre-trained Transformer 3 (kısaca GPT-3) , insanların yazdığı metinlere benzer içerik üretmek için derin öğrenmeyi kullanan özbağlanımlı dil modelidir."Elde etmeniz gereken boşluk içermeyen bir metinse bu bilgiyi de fonksiyon içeriğinde belirterek (sep="") uygun çıktıyı elde edebilirsiniz.
paste("bir","iki","üç","dört", sep="")## [1] "birikiüçdört"
Benzer şekilde boşluklar farklı sembollerle de doldurulabilir.
paste("bir","iki","üç","dört", sep="**")## [1] "bir**iki**üç**dört"paste("bir","iki","üç","dört", sep="--")## [1] "bir--iki--üç--dört"Metin içerisinde belli bir kısmı almak istediğinizde substr komutu işlemi kolaylıkla gerçekleştirecektir.
x<-"OpenAI, kâr amacı gütmeyen bir yapay zeka araştırma şirketidir."
substr(x,start=32 ,stop=41)## [1] "yapay zeka"5.6.3 Faktörler (Factors)
Faktörler, kategorik verileri temsil etmek için kullanılır ve sıralanmamış veya sıralanmamış olabilir. Kategorik veriler, veri biliminde önemli bir rol oynamaktadır. Bir faktör, her tam sayının bir etikete sahip olduğu bir tamsayı vektörü olarak düşünülebilir.
Faktör nesneleri, factor() işlevi ile oluşturulabilir.
k<-factor(c("evet","hayır","evet","evet","evet","hayır"));k## [1] evet hayır evet evet evet hayır
## Levels: evet hayırclass(k)## [1] "factor"table() fonksiyonu ile verideki faktörlerin sıklığını gözlemek mümkündür.
table(k)## k
## evet hayır
## 4 2Faktör seviyeleri varsayılan yapıda alfabetik olarak sıralanmaktadır, seviyelerin sırasına müdahale etmek levels komutu ile mümkündür.
k<-factor(c("evet","hayır","evet","evet","evet","hayır"));k # alfabetik## [1] evet hayır evet evet evet hayır
## Levels: evet hayırk2<-factor(c("evet","hayır","evet","evet","evet","hayır"), levels=c("hayır","evet"));k2## [1] evet hayır evet evet evet hayır
## Levels: hayır evetVerideki mevcut faktör seviyelerini yine levels komutu ile sorgulayabilirsiniz.
aylar<-factor(c("mart","ağustos","ekim","ocak", "nisan","eylül","haziran","temmuz","şubat",
"mayıs","kasım", "aralık"))
length(aylar)## [1] 12class(aylar)## [1] "factor"levels(aylar) #alfabetik## [1] "ağustos" "aralık" "ekim" "eylül" "haziran" "kasım" "mart"
## [8] "mayıs" "nisan" "ocak" "şubat" "temmuz"5.7 Eksik Gözlemler (Missing Values)
Eksik gözlemler veri setinde NA veya NaN olarak tanımlanmaktadır.
is.na()NA sorgulama için kullanılır.is.nan()NaN sorgulama için kullanılır.- NA integer veya character olabilir.
- NaN aynı zamanda NA iken tersi doğru değildir.
NA ve NaN içeren bir seri oluşturup mevcut olma durumunu sorgulamak istersek;
x <- c(1, 2, NA, 10, 3, NaN)
is.na(x)## [1] FALSE FALSE TRUE FALSE FALSE TRUEis.nan(x)## [1] FALSE FALSE FALSE FALSE FALSE TRUE